什么是缓存?
缓存(Cache)是计算机领域里的重要概念,是优化系统性能的重要手段。
为什么需要缓存?
链路漫长,网络时延不可控,浏览器使用http获取资源的成本比较高,把上次请求的数据进行缓存,下次请求时可直接使用缓存中的数据,避免再进行多次请求 - 应答,节约网络带宽,提高响应速度。
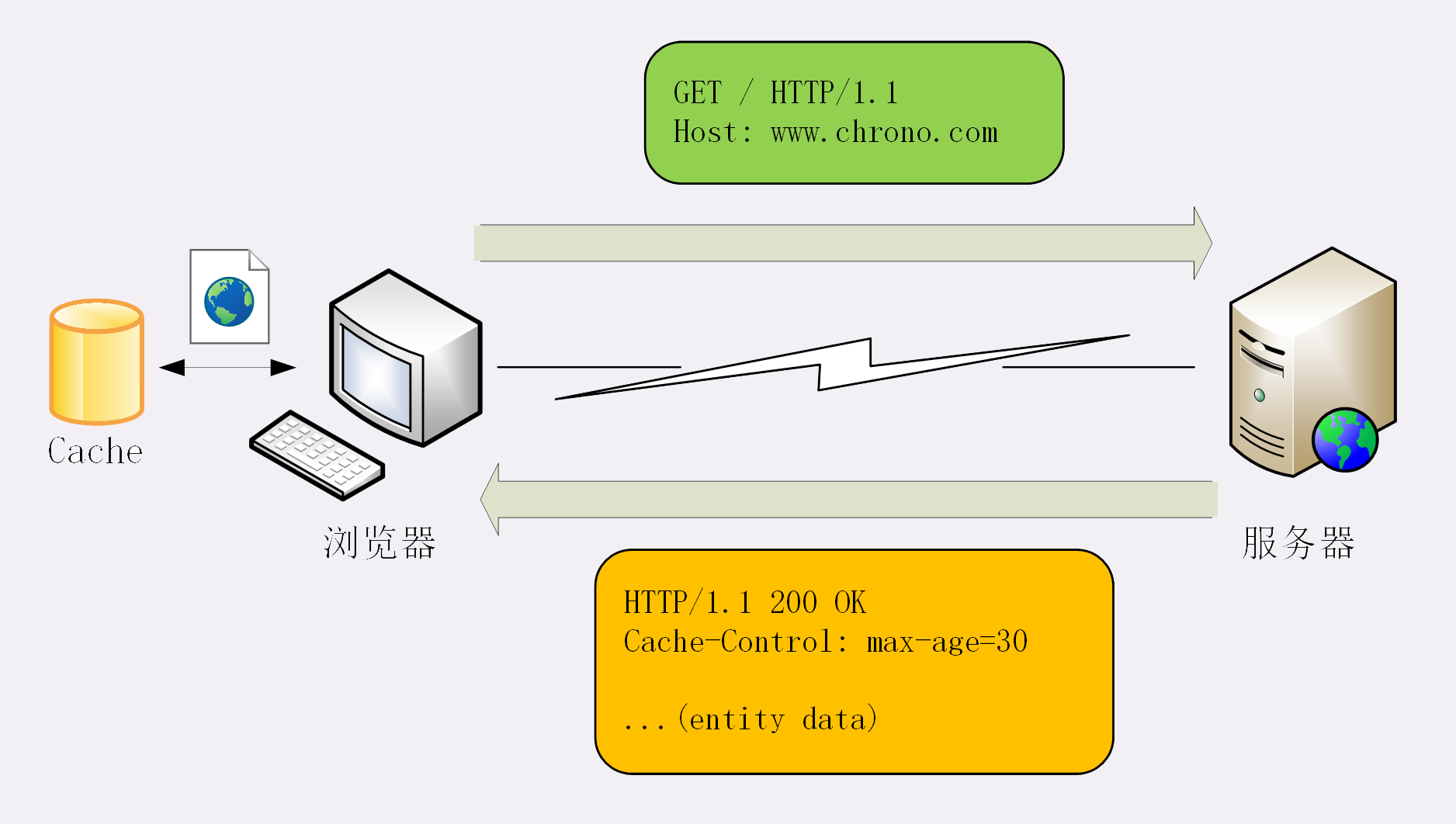
缓存的基本流程?
1.浏览器发现缓存无数据,则从浏览器获取相应的资源
2.服务器响应请求,返回资源,标记资源有效期
3.浏览器对资源进行缓存,再次请求在有效期内则使用缓存
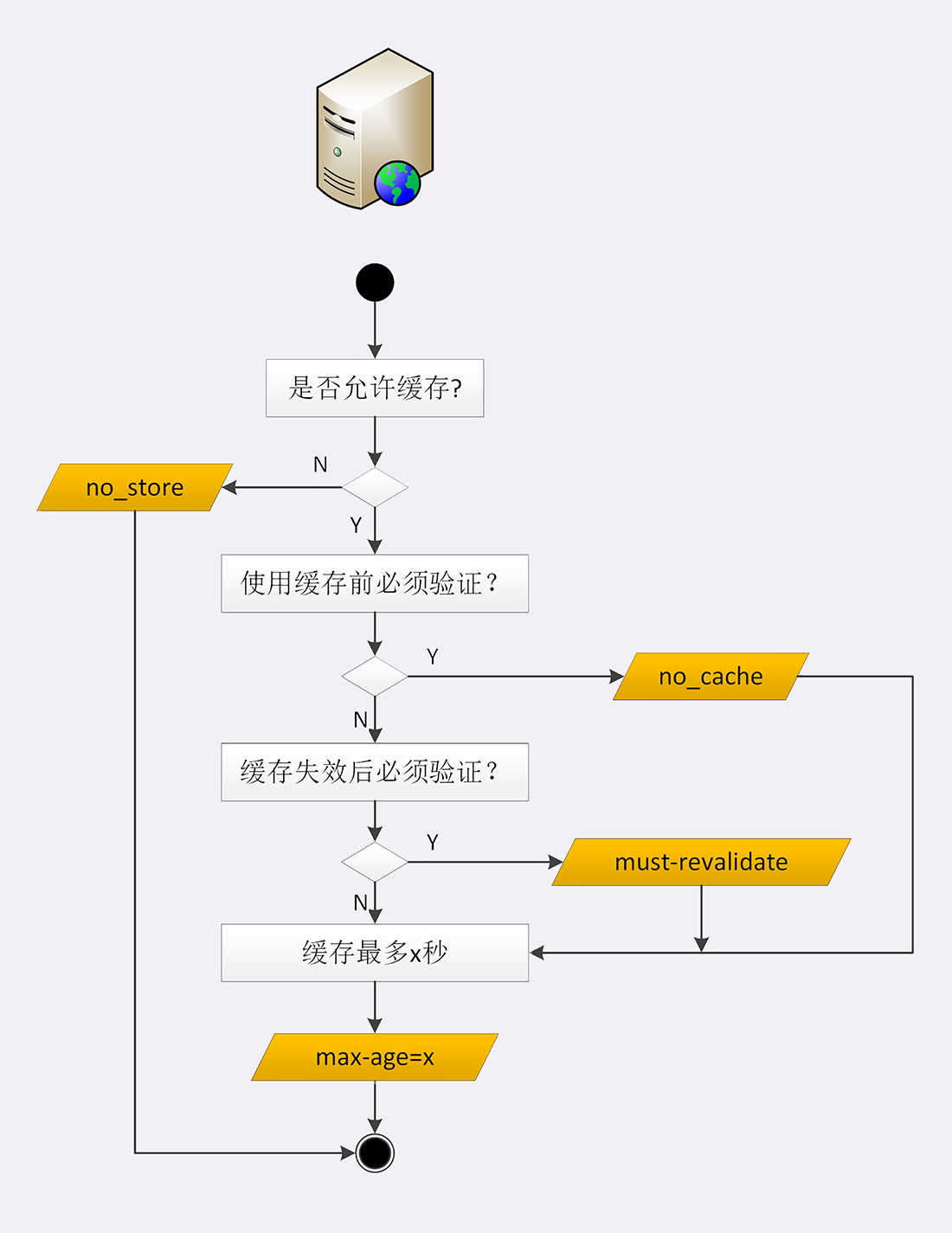
服务端控制缓存?
控制缓存通过请求/响应头中添加对应的缓存控制字段
响应头中添加 Cache-Control:max-age=30,意思为该资源的有效时间为30秒,max-age代表资源的生存期,时间是从浏览器响应时间开始计算,并不是指浏览器拿到响应数据的时间,因为这是服务端进行设置的,自然是站在服务端的角度。
max-age是缓存控制的基本属性,还有其他属性用来更精确的控制
1.no_store 不允许浏览器缓存,资源变化比较频繁的数据一般使用这个选项
2.no_cache 并不是是指不使用缓存,而是可以使用缓存,但每次使用都必须去服务端验证缓存是否失效
3.must_revaldate 缓存不过期则可以继续使用,过期后再去服务端验证,不需要每次进行验证
客户端控制缓存?
客户端控制缓存也是使用Cache-Control请求头字段,请求方和响应方都可以使用这个字段进行缓存控制,互相协商。
常见场景:
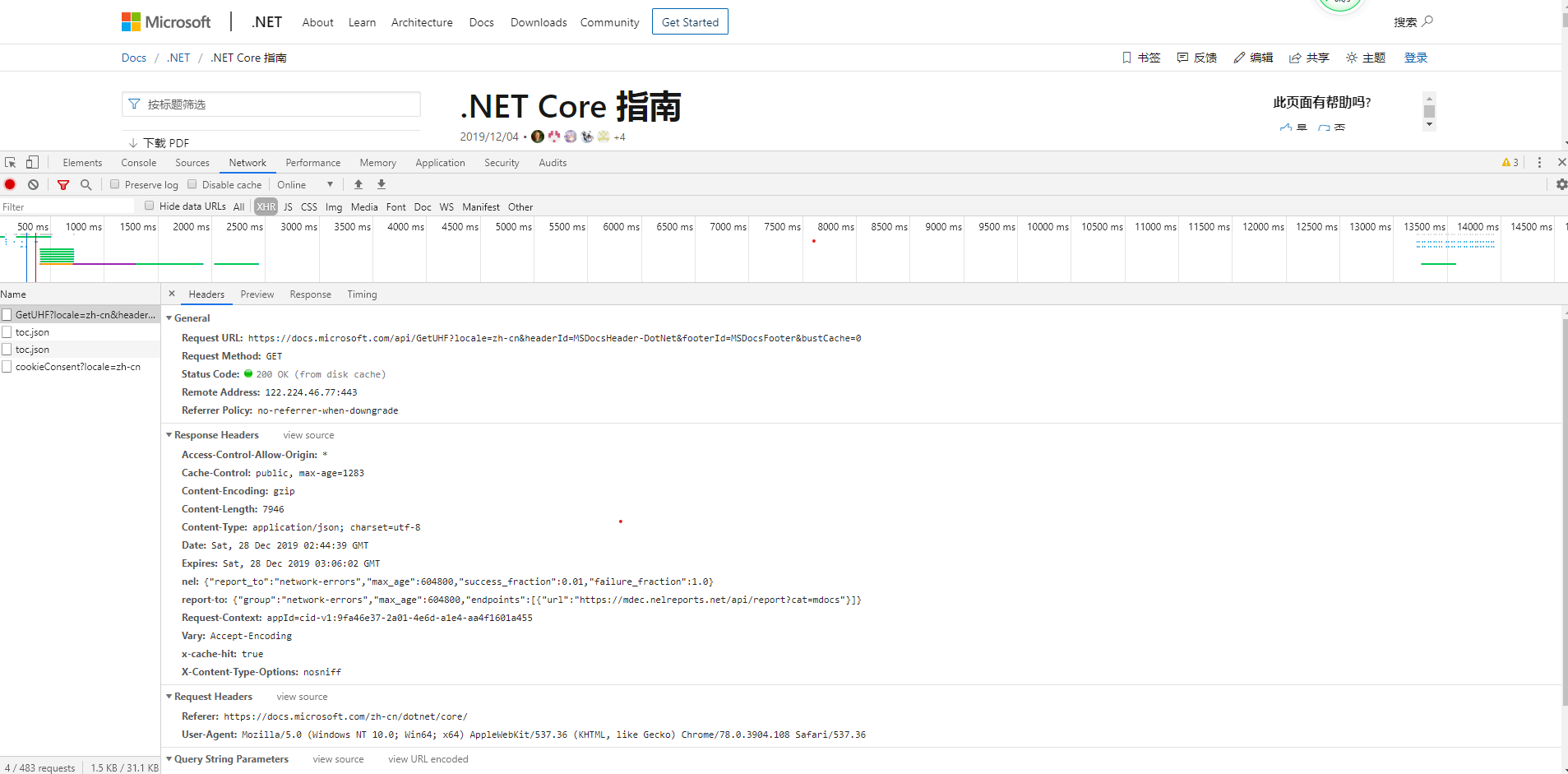
1.F5刷新页面
浏览器在请求头中添加Cache-Control:max=age=0 ,希望服务端返回最新的数据
2.Ctrl + F5 强制刷新页面
浏览器在请求头中添加Cache-Control:no_cache,检查是否有最新的数据,有则返回
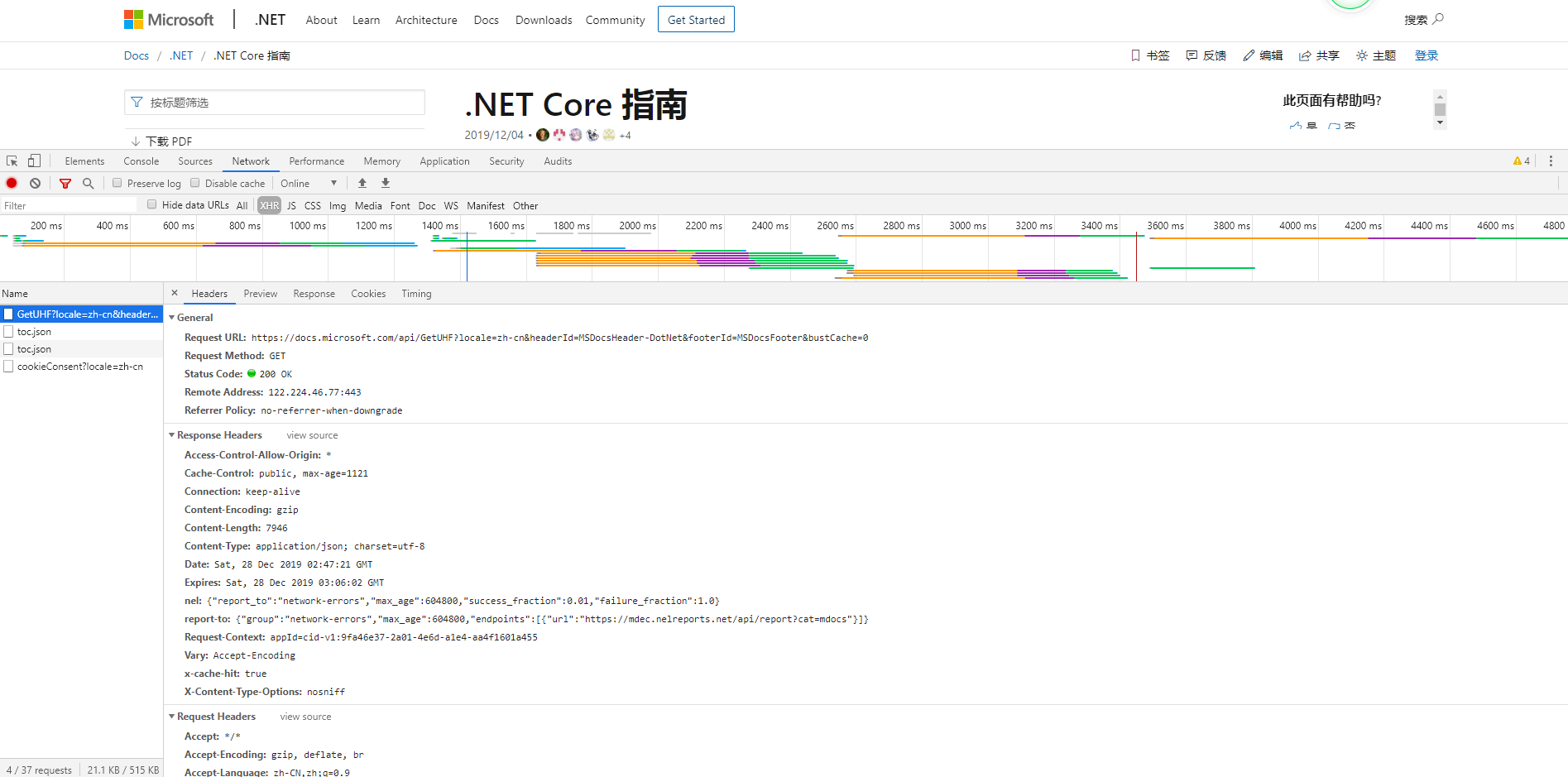
二者的效果通常是一致的
条件请求
浏览器用“Cache-Control”做缓存控制只能是刷新数据,但是如何去验证数据是否过期是否有效却做不到,需要通过其他方式实现。
1.浏览器使用两个请求
第一步 先发送一个最简单的Head请求,获取资源的元信息,判断缓存的资源是否过期
第二步 如果对比后资源过期,则使用Get请求获取新数据
但是因为需要使用两个请求才能完成验证,所以HTTP协议定义了一系列If开头的条件请求字段,专门用于检测资源是否过期,将验证工作整合在一次请求中,由服务端进行验证工作。
条件请求一共有 5 个头字段,我们最常用的是“if-Modified-Since”和“If-None-Match”这两个。需要第一次的响应报文预先提供“Last-modified”和“ETag”,然后第二次请求时就可以带上缓存里的原值,验证资源是否是最新的。
如果资源没有变,服务器就回应一个“304 Not Modified”,表示缓存依然有效,浏览器就可以更新一下有效期,然后放心大胆地使用缓存了。
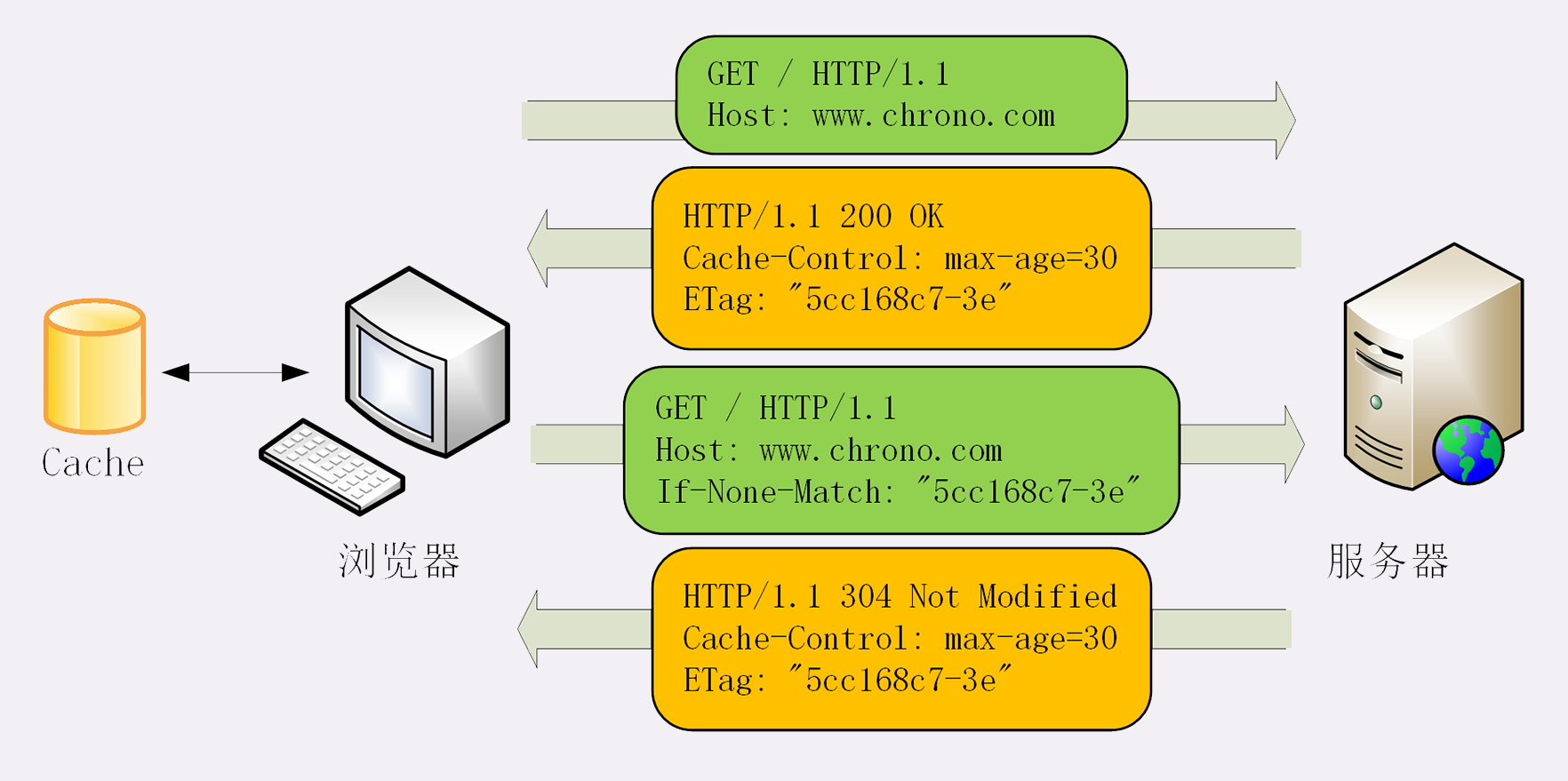
Last-modified : 文件的最后修改时间
ETag : “实体标签”(Entity Tag)的缩写,是资源的一个唯一标识,主要是用来解决修改时间无法准确区分文件变化的问题。
ETag 还有“强”“弱”之分。强 ETag 要求资源在字节级别必须完全相符,弱 ETag 在值前有个“W/”标记,只要求资源在语义上没有变化,但内部可能会有部分发生了改变(例如 HTML 里的标签顺序调整,或者多了几个空格)。